


I. Introduction▲
Avant-propos▲
Pourquoi vouloir agréger des partitions ?▲
- Pour bénéficier de disques virtuels très grands
Les disques deviennent de plus en plus gros, mais tout comme les besoins en stockage.
Vous vous apercevrez souvent que vous avez besoin d'un système de fichiers plus grand que les disques que vous avez à votre disposition. - Pour créer de la redondance, ce qui permettra de restaurer les données en cas de défaillance matérielle
- Pour améliorer les performances
En multipliant le nombre d'accès concurrent, on réduit considérablement les performances globales du système… Il devient alors très pratique de répartir la charge sur différents disques.
Organisation des disques sous BSD▲
Sur une machine BSD, les disques sont placés dans /dev avec des points de montage du type /dev/adX pour les disques ide, et /dev/daX pour les disques scsi. Sur ces disques, on crée des partitions avec les conventions suivantes :
|
Partition |
Convention |
|---|---|
|
a |
Contient normalement le système de fichiers racine |
|
b |
Contient normalement l'espace de pagination |
|
c |
Normalement de la même taille que la tranche slice contenant les partitions. Cela permet aux utilitaires devant agir sur l'intégralité de la tranche (par exemple un analyseur de blocs défectueux) de travailler sur la partition c. Vous ne devriez normalement pas créer de système de fichiers sur cette partition. |
|
d |
La partition d a eu dans le passé une signification spécifique, c'est terminé maintenant. À ce jour, quelques outils peuvent fonctionner curieusement si on leur dit de travailler sur la partition d, aussi on ne créera normalement pas de partition d. |
Chaque partition contenant un système de fichiers est stockée dans ce qu'on appelle une tranche, ou slice, numérotée de 1 à 4. Les numéros de tranche suivent le nom du périphérique, avec le préfixe s.
Il ne peut y avoir que quatre tranches physiques sur un disque, mais vous pouvez avoir des tranches logiques dans des tranches physiques, numérotées à partir de 5. Elles sont utilisées par des systèmes de fichiers qui s'attendent à occuper une tranche entière.
Les tranches, les disques « en mode dédié », et les autres disques contiennent des partitions, qui sont représentées par des lettres allant de a à h. Cette lettre est ajoutée au nom de périphérique.
En conclusion chaque disque présent sur le système est identifié. Le nom d'un disque commence par un code qui indique le type de disque, suivi d'un nombre, indiquant de quel disque il s'agit. Contrairement aux tranches, la numérotation des disques commence à 0.
Divers▲
Ce tutoriel va décrire cette opération pour des systèmes BSD, bénéficiant de gvinum
En ce qui concerne Linux, il existe LVM décrit par Sylvain Luce dans son tutoriel.
I-1. Présentation▲
I-1-1. GVinum▲
GVinum est un gestionnaire de volume, un pilote de disques virtuels.
I-1-2. Concaténation (JBOD)▲
La méthode la plus évidente est de diviser le disque virtuel en groupes de secteurs consécutifs de taille égale aux disques physiques individuels et de les stocker de cette manière. Cette méthode est appelée concaténation et a pour avantage que les disques n'ont pas besoin d'avoir de rapport spécifique au niveau de leur taille respective.
Cela fonctionne bien quand l'accès au disque virtuel est réparti de façon identique sur son espace d'adressage.
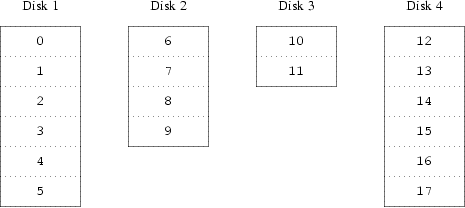
- On peut ajouter des disques ultérieurement.
- Les slices peuvent être quelconques.
- La perte d'un disque n'entraine pas d'autre perte de données… pas mal pour les données non critiques ;)
I-1-3. Raid-0 (Striping)▲
Une organisation alternative est de diviser l'espace adressable en composants plus petits, de même taille et de les stocker séquentiellement sur différents périphériques. Par exemple, les 256 premiers secteurs peuvent être stockés sur le premier disque, les 256 secteurs suivants sur le disque suivant et ainsi de suite. Après avoir atteint le dernier disque, le processus se répète jusqu'à ce que les disques soient pleins. Cette organisation est appelée striping (découpage en bande ou segmentation) ou RAID-0.
La segmentation exige légèrement plus d'efforts pour localiser les données.
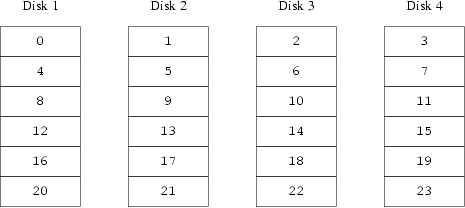
- On ne peut pas ajouter de disques ultérieurement.
- La perte d'un disque entraine la perte de toutes les données… déconseillé dans les serveurs de fichiers ;)
I-1-4. Raid-1 (Mirroring)▲
Le RAID 1 consiste en l'utilisation de disques redondants, c'est-à-dire n disques (en général deux), sur lesquels sont copiées exactement les mêmes données.
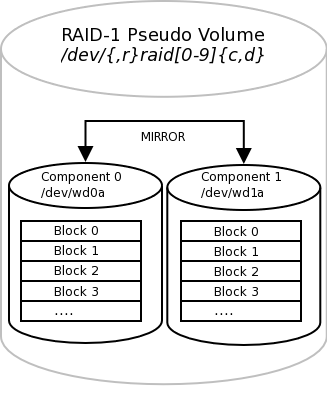
- On ne peut pas ajouter de disques ultérieurement.
- Les slices doivent être identiques.
- Demande au moins deux fois plus d'espace disque réel.
- Les écritures doivent être effectuées sur les deux disques
- La perte d'un disque n'entraine aucune perte de données… conseillé pour de petites capacités.
I-1-5. Raid-5▲
Le RAID 5 consiste en l'utilisation d'un calcul de parité des données, afin d'introduire la redondance nécessaire à la reconstruction des données en cas de panne matérielle. Il existe plusieurs méthodes (raid 3 et 4), mais celle-ci semble être la plus efficace…
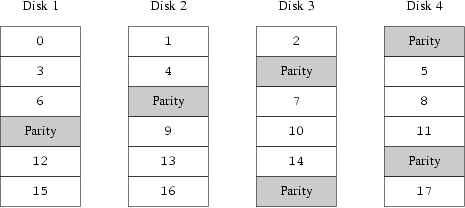
- On ne peut pas ajouter de disques ultérieurement.
- Les slices doivent être identiques.
- Demande exactement un tiers d'espace disque réel en plus.
- La perte d'un disque n'entraine aucune perte de données… conseillé pour de grosses capacités.
I-1-6. Divers▲
Il faut savoir que ces méthodes peuvent être mixées pour obtenir plus de performances, plus de tolérance aux pannes.
Ici on supporte au plus la perte d'un disque, etc.
N'hésitez pas à vous renseigner…